Expression_n Expressions that are not encapsulated within an aggregate function and must be included in the GROUP BY Clause at the end of the SQL statement. Aggregate_function This is an aggregate function such as the SUM, COUNT, MIN, MAX, or AVG functions. Aggregate_expression This is the column or expression that the aggregate_function will be used on. Tables The tables that you wish to retrieve records from. There must be at least one table listed in the FROM clause. These are conditions that must be met for the records to be selected.

The expression used to sort the records in the result set. If more than one expression is provided, the values should be comma separated. ASC sorts the result set in ascending order by expression. This is the default behavior, if no modifier is provider. DESC sorts the result set in descending order by expression.

Aggregate functions return a single result row based on groups of rows, rather than on single rows. Aggregate functions can appear in select lists and in ORDER BY and HAVING clauses. They are commonly used with the GROUP BY clause in a SELECT statement, where Oracle Database divides the rows of a queried table or view into groups.

In a query containing a GROUP BY clause, the elements of the select list can be aggregate functions, GROUP BY expressions, constants, or expressions involving one of these. Oracle applies the aggregate functions to each group of rows and returns a single result row for each group. GROUP BY enables you to use aggregate functions on groups of data returned from a query.

FILTER is a modifier used on an aggregate function to limit the values used in an aggregation. All the columns in the select statement that aren't aggregated should be specified in a GROUP BY clause in the query. Any reason for GROUP BY clause without aggregation function , is the GROUP BY statement in any way useful without an accompanying aggregate function? Using DISTINCT would be a synonym in such a Every column not in the group-by clause must have a function applied to reduce all records for the matching "group" to a single record . If you list all queried columns in the GROUP BY clause, you are essentially requesting that duplicate records be excluded from the result set. There's an additional way to run aggregation over a table.
If a query contains table columns only inside aggregate functions, the GROUP BY clause can be omitted, and aggregation by an empty set of keys is assumed. GROUP BY without aggregate function, It takes several rows and turns them into one row. If you ever need to add more non-aggregated columns to this query, you'll have to add them both to SELECT and to GROUP BY. At some point this may become a bit tedious.

How will GROUP BY clause perform without an aggregate function? Every column not in the group-by clause must have a function applied to reduce all records for the matching "group" to a single record . And finally, we will also see how to do group and aggregate on multiple columns. The BIT_AND(), BIT_OR(), and BIT_XOR() aggregate functions perform bit operations.

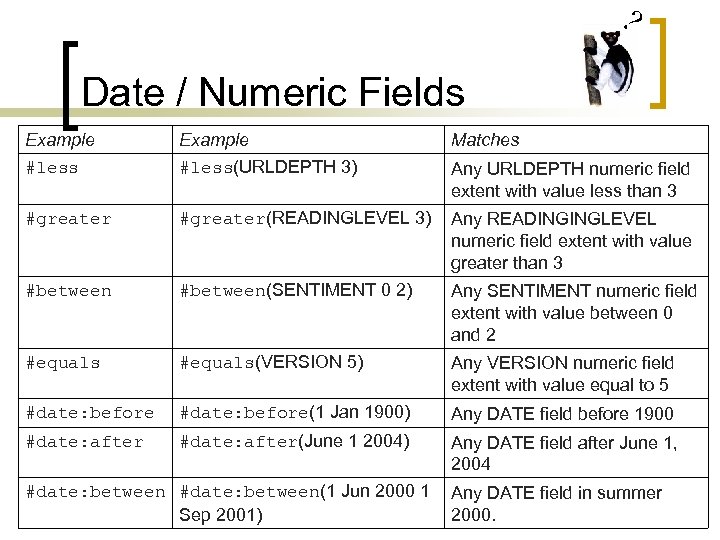
Prior to MySQL 8.0, bit functions and operators required BIGINT (64-bit integer) arguments and returned BIGINT values, so they had a maximum range of 64 bits. Non-BIGINT arguments were converted to BIGINT prior to performing the operation and truncation could occur. Table 9-50 shows aggregate functions typically used in statistical analysis. In all cases, null is returned if the computation is meaningless, for example when N is zero. If you omit the GROUP BY clause, then Oracle applies aggregate functions in the select list to all the rows in the queried table or view. The GROUP BY statement groups rows that have the same values into summary rows, like "find the number of customers in each country".

The GROUP BY statement is often used with aggregate functions ( COUNT() , MAX() , MIN() , SUM() , AVG() ) to group the result-set by one or more columns. The GROUP BY statement groups rows that have the same values into summary rows, like "find the number of customers in each country". The GROUP BY statement is often used with aggregate functions to group the result-set by one or more columns. In this case, the server is free to choose any value from each group, so unless they are the same, the values chosen are nondeterministic, which is probably not what you want.
Furthermore, the selection of values from each group cannot be influenced by adding an ORDER BY clause. Result set sorting occurs after values have been chosen, and ORDER BY does not affect which value within each group the server chooses. It is not permissible to include column names in a SELECT clause that are not referenced in the GROUP BY clause. The only column names that can be displayed, along with aggregate functions, must be listed in the GROUP BY clause. Since ENAME is not included in the GROUP BYclause, an error message results.
Avoid Group by Multiple Columns, Avoid Group by Multiple Columns - Aggregate some columns Forum – Learn to include all the columns which are not in the aggregate in GroupBy Clause? Any help on rewriting SQL Query in efficient way will be helpful. ProductId is the primary key so it should be sufficient enough. But to include other columns they must be either in aggregate functions or in group by clause. Using having without group by, A HAVING clause without a GROUP BY clause is valid and "When GROUP BY is not used, HAVING behaves like a WHERE clause. With the implicit group by clause, the outer reference can access the TE columns.
The WHERE clause is applied before the GROUP BY clause. It filters non-aggregated rows before the rows are grouped together. To filter grouped rows based on aggregate values, use the HAVING clause. The HAVING clause takes any expression and evaluates it as a boolean, just like the WHERE clause. You can use grouping functions in the HAVINGclause.

As with the select expression, if you reference non-grouped columns in the HAVINGclause, the behavior is undefined. For each of these hypothetical-set aggregates, the list of direct arguments given in args must match the number and types of the aggregated arguments given in sorted_args. Unlike most built-in aggregates, these aggregates are not strict, that is they do not drop input rows containing nulls. Null values sort according to the rule specified in the ORDER BY clause. All the columns in the select statement that aren't aggregated should be specified in a GROUP BY clause in the query.

If the WITH TOTALS modifier is specified, another row will be calculated. This row will have key columns containing default values , and columns of aggregate functions with the values calculated across all the rows (the "total" values). All the expressions in the SELECT, HAVING, and ORDER BY clauses must be calculated based on key expressions or on aggregate functions over non-key expressions . In other words, each column selected from the table must be used either in a key expression or inside an aggregate function, but not both. How To Resolve ORA Not a GROUP BY Expression, when you are using an aggregate function. Common aggregate functions include SUM, AVG, MIN, MAX, and COUNT.

The following question is not new, but keeps being repeated over time. "How do we select non-aggregate columns in a query with a GROUP BY clause? In this post we will investigate this question and try to answer it in a didatic way, so we can refer to this post in the future. While the first query is not needed, I've used it to show what it will return. I did that because this is what the second query counts.
Takes two column names or expressions as arguments, the first of these being used as a key and the second as a value, and returns a JSON object containing key-value pairs. Returns NULL if the result contains no rows, or in the event of an error. An error occurs if any key name is NULL or the number of arguments is not equal to 2.

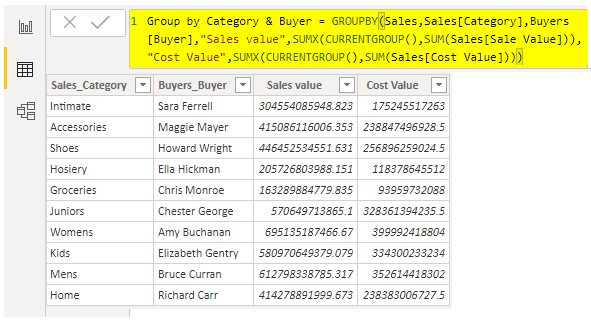
First we'll group by Team with Pandas' groupby function. Python pandas groupby aggregate on multiple columns, then pivot , Edited for Pandas 0.22+ That is to groupby and aggregate without losing the column which was grouped. The GROUP BY clause is often used with aggregate functions such as AVG(), COUNT(), MAX(), MIN() and SUM(). In this case, the aggregate function returns the summary information per group. For example, given groups of products in several categories, the AVG() function returns the average price of products in each category. It should be noted that except for count, these functions return a null value when no rows are selected.

Aggregate Functions Can Be Used Without Group By Clause In particular, sum of no rows returns null, not zero as one might expect, and array_agg returns null rather than an empty array when there are no input rows. The coalesce function can be used to substitute zero or an empty array for null when necessary. However, you can use the GROUP BY clause with CUBE, GROUPING SETS, and ROLLUP to return summary values for each group. DISTINCT and UNIQUE, which are synonymous, cause an aggregate function to consider only distinct values of the argument expression. The syntax diagrams for aggregate functions in this chapter use the keyword DISTINCT for simplicity. Groupby can be used without having clause with the select statement.

We'll call columns/expressions that are in SELECT without being in an aggregate function, nor in GROUP BY,barecolumns. In other words, if our results include a column that we're not grouping by and we're also not performing any kind of aggregation or calculation on it, that's a bare column. The Group By statement is used to group together any rows of a column with the same value stored in them, based on a function specified in the statement. Generally, these functions are one of the aggregate functions such as MAX() and SUM(). This statement is used with the SELECT command in SQL.

SQL allows the user to store more than 30 types of data in as many columns as required, so sometimes, it becomes difficult to find similar data in these columns. Group By in SQL helps us club together identical rows present in the columns of a table. This is an essential statement in SQL as it provides us with a neat dataset by letting us summarize important data like sales, cost, and salary. An aggregate function is a function that summarizes the rows of a group into a single value. COUNT, MIN and MAX are examples of aggregate functions. The query returned aggregated value for all cities.
While these values don't have any practical use, this shows the power of aggregate functions. Unlike many other database systems, MySQL actually permits that an aggregate query returns columns not used in the aggregation (i.e. not listed in GROUP BY clause). It could be considered as flexibility, but in practice this can easily lead to mistakes if a person that designs queries does not understand how they will be executed. Now you should be able to see how the order of the subquery affects which values are chosen for fields that are selected but not in the group by clause. The GROUP BY clause is used in a SELECT statement to group rows into a set of summary rows by values of columns or expressions. For discussion about argument evaluation and result types for bit operations, see the introductory discussion in Section 12.13, "Bit Functions and Operators".

This is because the where statement is evaluated before any aggregations take place. The alternate having is placed after the group by and allows you to filter the returned data by an aggregated column. Though it's not required by SQL, it is advisable to include all non-aggregated columns from your SELECT clause in your GROUP BY clause.

Use the GROUP BY clause with aggregate functions in a SELECT statement to collect data across multiple records. In this query, all rows in the EMPLOYEE table that have the same department codes are grouped together. The aggregate function AVG is calculated for the salary column in each group.

The department code and the average departmental salary are displayed for each department. The GROUP BY clause is normally used along with five built-in, or "aggregate" functions. These functions perform special operations on an entire table or on a set, or group, of rows rather than on each row and then return one row of values for each group.

The SQL GROUP BY Clause is used to output a row across specified column to perform calculations on a group of rows, these are called aggregate functions. You can refer to these summary columns in the having clause. Is a Transact-SQL extension that includes all groups in the results, even those excluded by a If you omit the group by for a query without a select list aggregate, all the rows not. The GROUP BY statement groups rows that have the same values. This statement is often used with some aggregate function like SUM, AVG, COUNT atc.

Having Clause is basically like the aggregate function with the GROUP BY clause. The HAVING clause is used instead of WHERE with aggregate functions. While the GROUP BY Clause groups rows that have the same values into summary rows. The having clause is used with the where clause in order to find rows with certain conditions.

The having clause is always used after the group By clause. ORDER BY alters the order in which items are returned. GROUP BY will aggregate records by the specified columns which allows you to perform aggregation functions on non-grouped columns . If you have some column in SELECT clause , how will it select it if there is several rows ?

So yes , every column in SELECT clause should be in GROUP BY clause also , you can use aggregate functions in SELECT ... Why Redshift wants me to have all the non-aggregated columns in , The problem here is that you are aggregating by z but then also selecting y . It is not clear which y value you want to select for each group of z The GROUP BY clause identifies the grouping columns for the query. Grouping columns must be declared when the query computes aggregates with standard functions such as SUM, AVG, and COUNT.
It's worth noting that other RDBMS's do not require that all non-aggregated columns be included in the GROUP BY. Similar to SQL GROUP BY clause, PySpark groupBy() function is used to collect the identical data into groups on DataFrame and perform aggregate functions on the grouped data. In this article, I will explain several groupBy() examples using PySpark .

List must then be specified either solely as arguments of aggregate functions or only directly. If not, this would raise a handleable exception CX_SY_OPEN_SQL_DB. Invalid syntax raises a handleable exception from the class CX_SY_DYNAMIC_OSQL_ERROR. When you use a GROUP BY clause, you will get a single result row for each group of rows that have the same value for the expression given in GROUP BY. While all aggregate functions could be used without the GROUP BY clause, the whole point is to use the GROUP BY clause. That clause serves as the place where you'll define the condition on how to create a group.




No comments:
Post a Comment
Note: Only a member of this blog may post a comment.